

When customers make decisions about installing apps in cloud, they ask a series of questions to ensure their data is protected and they're able to meet compliance requirements. Often, an important question customers ask is, where does this app store data? Will I have the option to keep my data in a region that I trust?
To ease some of these concerns, last quarter, platinum Marketplace Partner K15t used Atlassian's realm pinning and realm migration APIs and services to implement data residency.
At last month's Developer Day, we heard from software engineer Fabian Siegel about his team's experience enabling data residency for K15t's popular Scroll Exporter apps.

You can find a recording and summary of the key takeaways from K15t's presentation below.
What is data residency?
Data residency gives organizations more control over their data by ensuring any in-scope data (ideally this would include personal or sensitive customer data) is stored within a region they trust. Many organizations care about data residency and see it as a requirement to do business with a SaaS vendor. Data residency can also make it easier for companies to meet regulatory obligations related to data localization and transport.
To help customers meet data residency needs, Atlassian offers data residency for Jira family and Confluence products in the US, the EU, Germany, Australia, and Singapore. Atlassian also offers APIs and services so that apps built on Connect can offer:
- Realm pinning: Allows customers to select a location where the app can be installed to and where in-scope app data must be stored.
- Realm migration: Allows customers to migrate their app data between supported locations after the app was installed.
You can see Atlassian's planned data residency regions in our public roadmap.
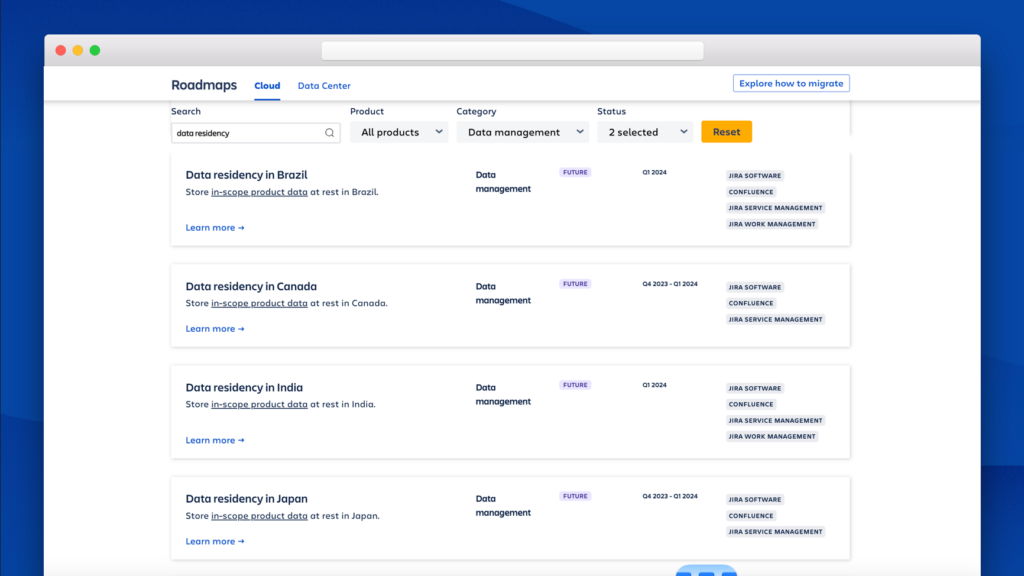
Why did K15t choose to invest in data residency?
K15t had two main reasons for offering data residency:
They wanted to give customers more control over their data.
K15t wants their apps to be available to as many customers as possible. Enabling customers to have more control over where app data is hosted allows customers with strict data protection requirements to use K15t's apps in cloud.
They wanted to help their existing customers move to cloud.
K15t still has customers on server and Data Center who would like to move to cloud, but need apps that offer data residency in order to migrate. Supporting data residency allows those customers to move to cloud with the K15t apps they love.
With these objectives in mind, K15t set out to implement realm pinning and realm migration for their Scroll Exporter apps.
Implementing realm pinning
Implementing realm pinning took place in 3 stages for Fabian's team:
First, they needed to ensure their app could run in multiple regions.
They did this by deploying their app's whole infrastructure (which was located in the US) into Europe. This was relatively straightforward, because the scroll apps are built using an Infrastructure as Code template in AWS CloudFormation. In CloudFormation, they were able to simply choose a new deployment region to deploy the app in Europe.
K15t did have a few region-based things hard coded that needed to be adjusted, but for the most part it was easy to deploy their infrastructure in new regions.
Then, they needed to create region-specific baseUrls.
K15t also changed their apps’ base URLs so that they could add a region (ex: scrollpdf.addons.k15t.com became scrollpdf.us.exporter.k15t.app and scrollpdf.de.exporter.k15t.app).
Then, they updated their app descriptor.
This just involved adding region-specific baseUrls to the regionBaseUrl object in their app descriptor. This makes it possible for your app to be automatically installed in the correct region based on the region of the parent product. For example, if someone installs your app in a Confluence instance that has data pinned to Germany, the Germany baseUrl is chosen and the app data is also pinned in Germany.

Implementing realm migration
Last month, Atlassian rolled out a new data residency self-service UI for apps, so customers can view and manage app data residency in the same place they manage data residency for Jira and Confluence.
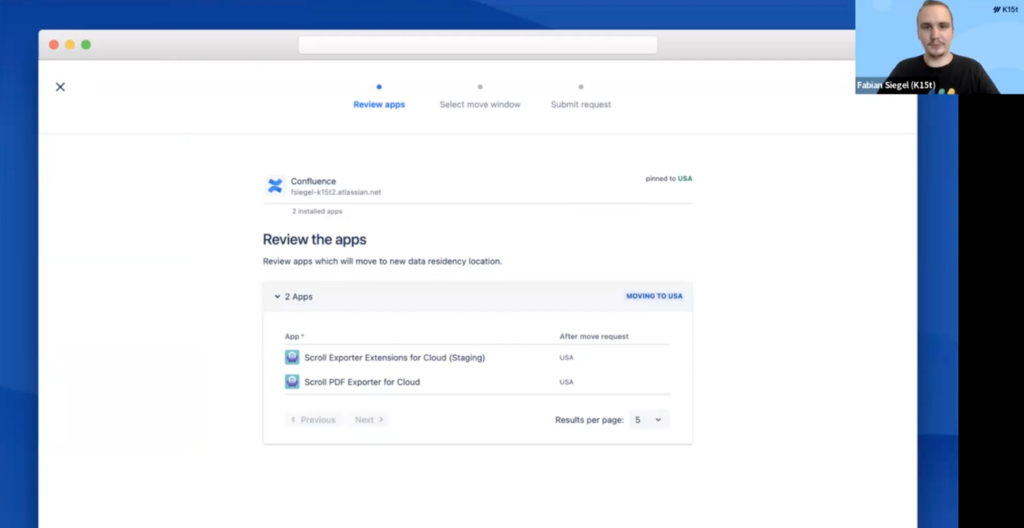
This new experience allows customers to request app data migration for "eligible" apps. Eligible apps are apps that:
- independently offer realm pinning in the same location as the host product
- support realm migration
- are not currently pinned to the same location as the host product.
With this new UI, customers can select a 24 hour window of time for their instance to go offline so app data can safely be moved.
In order to help their existing customers easily move and pin data for already installed apps, K15t just needed to go to the lifecycle object in their Connect descriptor, and add in a "dare-migration" hook beside the existing "installed" and "uninstalled" hooks. This allowed migration events to be sent to the relevant path for their apps.

Once they subscribed to the realm migration events from the app realm migration service, they started receiving the following hooks:
- /schedule (post): This lets you know when a realm migration has been scheduled
- /start (post): This lets you know when the migration window is beginning for a given instance
- /status (get): This allows K15t to check the status of their app's realm migration
- /commit (post): This allows you to commit your app data to a new region
- /rollback (post): This is here in case something goes wrong and you need to roll back the change
How does K15t handle realm migration events?
/schedule events
When a customer scheduled a realm migration for an app, the realm migration service sends a /schedule event with the following information:
- start time
- end time
- target location
To handle these events, K15t set up a new realm migration database to record this information along with the tenant requesting the move (and associated tenant information), and an assigned Migration ID to keep track of the request. They also set up error codes to reject migrations for various reasons like unsupported regions or too many concurrent requests.
/start events
This is where K15t spent the bulk of their time when implementing realm migration. They had to think about what data needed to be copied and moved, and what data could be deleted (ex: cached data does not necessarily need to be migrated).
These events contain the same basic info as the /schedule events, so the first thing K15t does when they receive a /start event is to verify that it matches the initial /schedule event for this tenant. Then they add a "copying" status to the database for this Migration ID to clarify that the migration has started.
Next, they start a separate "worker" instance to copy over the data to the new region. The concept of a "worker instance" was already familiar to K15t, as their Exporter apps run separate servers or "workers" using AWS Lambda and AWS ECS Tasks to handle the exporting function. They simply had to use the same concept to isolate the work needed to perform the migration to avoid any issues caused by large volumes of data being copied, or updates running at the same time as a migration is taking place.
This "worker" instance:
- gets the migration ID from the database
- copies over information from the source realm to the target realm, including:
- information associated with the tenant (ie: sharedSecret, clientKey etc)
- information necessary for the app to function
- marks the migration status as "ready-to-commit" in the database
/status events
The realm migration service regularly polls the /status hook to get the latest status on the migration for the customer.
K15t used the following statuses for their realm migration offering:
- "Scheduled": set when the migration is scheduled by the customer (if it is not rejected).
- "Copying": set when the migration window has begun and the worker instance is copying over data to the requested region.
- "Ready-to-commit": This lets the service know that the data is all copied to the new region and the migration is ready to be committed. This status is used by the /commit hook.
- "Failed": This lets the service know that the migration has failed, and triggers the /rollback hook.
Some of these statuses you can set yourself, but "ready-to-commit" and "failed" are important to remember and use, as they trigger other hooks in the migration service, which we'll cover below.
/commit events
Once your migration's status is marked as "ready to commit" you'll receive a /commit hook, which will give you the same information as the start and schedule hooks. K15t uses this information to verify again that the data was migrated to the correct realm and nothing has changed.
If nothing looks wrong here, they then set the status to "committing," and start another "worker instance" to delete the data from the old region, where it is no longer needed.
Once the data is deleted, the status is changed to "committed" and the migration is complete!
/rollback events
In the event that something goes wrong, K15t sets the migration status to "failed" which triggers the /rollback hook. They then set the migration status to "rolling back."
They then start a new worker instance which checks to see if all the data was copied over to the new region yet. If the copy job was not yet started, there's no need to do anything here and the migration is cancelled.
If the copy job was already started, the worker waits until it's done, and then undoes its work in the target region.

Testing & launch!
K15t worked directly with the Atlassian Developer Support team to test and debug their realm migration solution, running manual migrations without having to shut down their Confluence instance to test.
Once they were confident it worked, they emailed the Solution Partners they collaborate with most closely so they knew that K15t's Exporter apps could support customers with data residency needs, and customers who were waiting to move to cloud until key apps supported data residency.
Since launching, K15t has already seen customers using the realm migration feature!