

Jenkins to Jira: a new type of integration
Several weeks ago we launched the Jira Software Cloud plugin for Jenkins, available now on the Jenkins Plugin Index.
Similar to our other integrations with CI/CD tools, this integration allows teams to automatically send build and deployment information from Jenkins and display it across Jira issues and boards and query it via JQL. Teams using the integration will have up-to-date information about their Jenkins builds and any deployments on Jira issues with deep links to quickly investigate failed builds or deployments in Jenkins.
In order to build an integration between a cloud product and a behind-the-firewall product, we had to build a new way to integrate with Jira Software Cloud that doesn't expose it to security breaches. The solution is a new OAuth credential (2LO) which Jira admins can create in their Jira Cloud site. When created, this OAuth credential is explicitly scoped for additional security, so that it can only be used to send build and deployment information and associate that information with Jira issues. This gives your Jenkins server, operating behind the firewall, a mechanism to securely send data one-way to your Jira Cloud site without having to open up any ports in your firewall. (By the way, this is open source, so if you are interested in contributing to or forking this plug-in, you can head over to our project on the Jenkins GitHub repo to get started.)
The OAuth credential is currently scoped to only send build and deployment information via the Jira APIs, but we're excited about the potential to expand the scope of the OAuth credential to enable more behind-the-firewall apps to connect with our cloud products. For example, the API we're working on now includes commits, branches, and pull requests, which would allow customers to integrate Bitbucket Server/GitHub Enterprise/GitLab with Jira Software Cloud. Long-term, we hope to get a point where we can add support for new data types in less than a month, just by specifying the APIs. Stay tuned for more!
In the meantime, here is how we built the Jenkins to Jira integration using this new credential.
How we built it
From the Jenkins side
The Jenkins plugin was built using the Jenkins Pipeline API. The plugin consists of the following three components:
- Global configuration: where Jenkins admins can define Jira Cloud sites and the corresponding OAuth credentials
- jiraSendBuildInfo: Jenkins Pipeline Step that sends build information to Jira Cloud
- jiraSendDeploymentInfo: Jenkins Pipeline Step that sends deployment information to Jira Cloud
Global configuration
The plugin provides an additional section on the Manage Jenkins → Configure system screen. It allows you to configure Jira Cloud sites with the corresponding OAuth credentials. Credentials are encrypted and securely stored in the Jenkins credentials store.
jiraSendBuildInfo
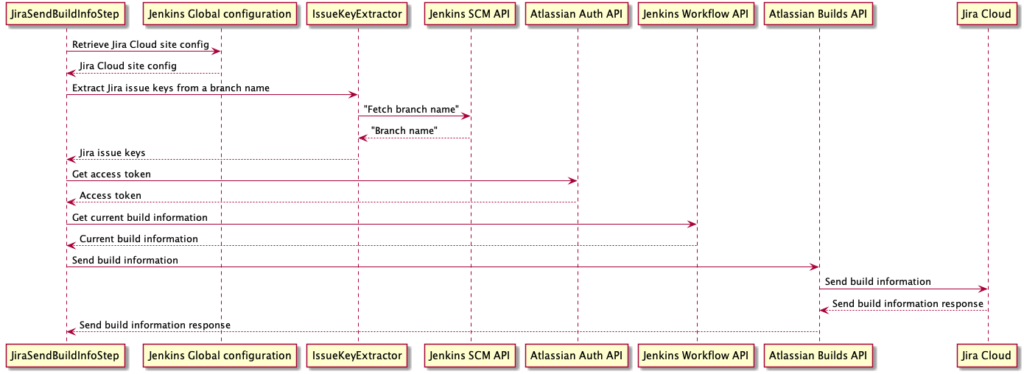
The jiraSendBuildInfo step has been designed as a post-build action. When added to a Jenkinsfile, it will collect and send current build information to Jira Cloud. The target Jira Cloud site name is provided as the step parameter. The site name parameter is used to retrieve the corresponding Jira Cloud site configuration from the Jenkins Global configuration (described above).
To associate Jenkins build information with Jira issues, the plugin looks for Jira issue keys in a branch name, e.g. branch name TEST-123-awesome-new-feature will be parsed and "TEST-123" will be extracted as a potential Jira issue key. By default, the branch name is fetched from the Jenkins SCM API. Alternatively, the branch name can be explicitly specified as an additional branch parameter. You can also use the branch parameter to post the build result to a specific Jira issue.
To send the build information to Jira, the plugin uses Jira Cloud Builds API.
The whole process of sending build information to Jira Cloud looks as follows:
jiraSendDeploymentInfo
The jiraSendDeploymentInfo step has been also designed as a post-build action. When added to a Jenkinsfile, it will collect and send current deployment information to Jira Cloud. The jiraSendDeploymentInfo expects the following parameters:
- site: e.g. "example.atlassian.net"
- environmentId: e.g "prod-east"
- environmentName: e.g. "Production East"
- environmentType: e.g. "production" (allowed values: “development”, “testing”, “staging”, “production”)
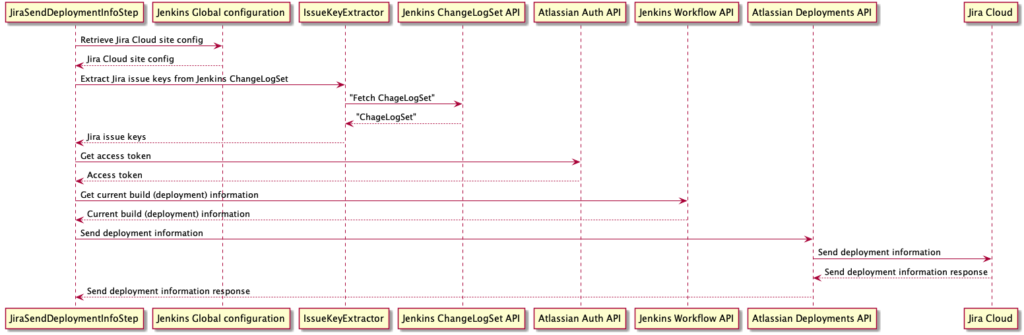
Similarly to jiraSendBuildInfo step, the site name parameter is used to retrieve the corresponding Jira Cloud site configuration from the Jenkins Global configuration (described above).
To associate Jenkins deployment with Jira issues, the plugin looks for Jira issue keys in commit messages. Specifically, the plugin uses the Jenkins ChangeLogSet API. For example if the Jenkins ChangeLogSet contains the following entries "TEST-123 First commit" and "TEST-345 Second commit", the plugin will extract "TEST-123" and "TEST-345" as potential Jira issue keys to associate the deployment information with.
To send the build information to Jira, the plugin uses Jira Cloud Deployments API.
The whole process of sending deployment information to Jira cloud looks as follows:
From the Jira side
There were three main challenges with building the Jira side of the integration:
- Keep the UI simple enough that a Jira admin without any developer experience can use it
- Ensure maximum security of credentials and Jira information
- Avoid adding code to the Jira monolith (the huge, original codebase, which we're slowly teasing apart into microservices)
The UI
Atlassian is currently in the process of moving all the front-end code into the Jira SPA (single-page application) built using REACT/Redux. When all of a user's navigation within the SPA, the perceived performance is almost an order of magnitude higher.
To simplify the process of adding modules to the SPA, we have a lot of internal tooling. We were lucky enough to be one of the first teams to use the latest version. This meant that almost all state-management, analytics, and AtlasKit components were already wired up for use.
Thanks to the internal front-end platform, we could focus on quickly shipping a simple design. This is generally a good approach, as it's hard to gauge what features customers will request next. One of the features we worried about cutting was the ability to edit. For example changing the name of an application. But so far, we haven't had any feature requests for it.
Security
The single most important aspect of the back-end was security. Before shipping to our initial cohort, we paired up with our security team to get a full audit of the microservice we built. This included ensuring that credentials cannot leak to logs, a common issue to miss if not filtering stack traces on errors.
Early on, we decided not to store any credentials in our service. A stateless service with no persistent store is a much smaller target for hacking or security problems.
We didn't manage to avoid storing any data, as this would limit our ability to create a full audit trail. However, the data we store is of no value to a hacker, as it only provides a means of traceability. It can't be used to access any private resources.
The main way to create integrations with Jira is Atlassian Connect. However, it has two design flaws:
- It requires a callback containing a shared secret, which means customers need to keep their firewall open for this callback to arrive
- It has a very coarse grained security model, meaning an app that has read scope can read any data about Jira issue
In this project, we decided to solve both these problems. Removing the callback means customers can integrate with products like Jenkins that run behind a firewall. This was a must-have for our enterprise customers.
The second issue was the security problem of coarse-grained scopes. We solved this by creating a separate OAuth scope for our integration. This means that if the credentials we create were somehow to leak, the data in Jira is still safe. Hence, the only thing that can be found out about Jira issues using credentials is whether or not a particular issue key is valid or not.
The only data that can be read, written, or deleted is the data that was written with the credentials themselves. In case of credentials leaking, this data is likely already exposed in the application that's sending data.
Avoid the monolith
Our team is quite far along on our microservice journey. Whenever we start a new project, one of our goals is to not write a single line of code in the Jira monolith. There are four reasons for this:
- The devloop is very slow; running a full branch in Bamboo build takes over an hour
- The release cycle is slow; it takes about two days to fully release a feature, while in our microservices we automatically release to production in under 20 minutes from merging a pull request
- The long-term future of Jira is to be split into microservices; if we add to the monolith, we create a moving target problem, slowing down the migration to microservices
- Our internal platform has a higher reliability and lower response times than the Jira monolith; eliminating all interaction with Jira means we provide a better customer experience
As mentioned before, we created a new microservice to provide the back-end functionality. This service is built in Kotlin on top of Spring Boot, with a single Dynamo table for audit trails.
All the functionality is provided by chaining together REST calls to our platform APIs. This meant we could build the core functionality in under 1000 lines of Kotlin.
One of the biggest challenges we faced is actually low traffic volume. As the apps are used for system to system integrations, they have a lifecycle of years and many customers never create any. This meant that we had to add frequent semantic monitoring to catch any issues with our dependencies. Otherwise, it may be days between a dependency breaking its API and us noticing the problem when a customer has an issue.
This is just the beginning
We're excited about the potential of the work we did to create this integration between Jenkins and Jira Software Cloud. Together we can unlock so many more use cases for our mutual customers with this new Server2Cloud integration type as we scope the API even further. For now, you can use the OAuth credential to create integrations between your behind-the-firewall CI/CD tool and Jira with build and deploy info, and we'll be sure to update you when more data types become available.
To simplify development, here is a separate downloadable API specification.