
Overview
In this post, I’m going to be giving you a brief overview of the great work the Cold Fusion team at Atlassian has been doing over the past 9 months on integrating DevOps into Automation for Jira.
Automation for Jira
Automation for Jira (AFJ) is a simple and powerful feature used to automate Jira. It was created by Code Barrel which was acquired by Atlassian in October 2019. Post-acquisition, the app was made available natively in Jira Cloud.
AFJ allows users to automate their Jira projects with a lot of flexibility. A handful of triggers are used to trigger certain actions that operate within your Jira board. For example, you can automatically transition, comment, or create issues based on some trigger.
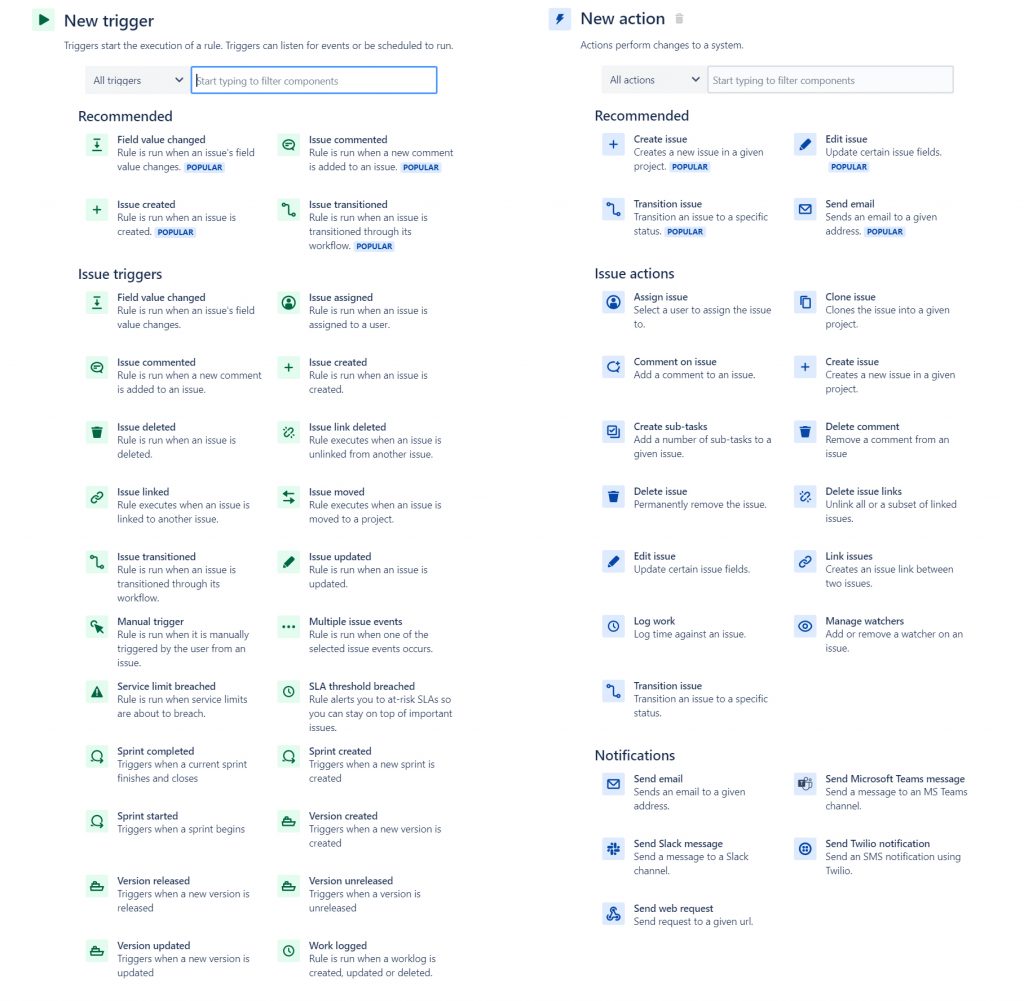
DevOps Automation
Atlassian realised the potential in extending this automation framework to add DevOps automation. The ability to action your Jira issues based on development triggers was a highly sought after feature from customers. At the very least users would be able to automatically transition their issues from the backlog → in progress → in review → done, all without ever manually transitioning an issue. No more “Hi team, has everybody updated their issues on the board” prompt from the team lead each standup.
However, this is only scratching the surface!
Thankfully, I was fortunate enough to be a part of the awesome Cold Fusion team that has worked hard over the past 9 months to make this desire a reality. We have added triggers for branches, commits, pull requests, builds and deployments to AFJ with support for all major git providers (including but not limited to Bitbucket, Github and Gitlab).
Project breakdown
While my team was working on adding DevOps integration to AFJ. The core AFJ team was working hard to make the app available natively. This was quite an interesting process as AFJ’s infrastructure lived in its own AWS account isolated from the Atlassian AWS account.
The main challenge in this project was effectively and reliably delivering development events from git providers to the AFJ system. Once the deployment messages reached the AFJ system, they would be wired to fire the corresponding trigger. For example, a commit created message would travel from the git provider through our system and finally reach AFJ which would trigger all rules that utilised the commit created trigger.
Luckily, there was some existing infrastructure that could be reused. We already have development information being sent from git providers like Bitbucket to Jira.
Jira Issue References
A Jira issue reference is the way in which we link development information to a Jira issue. There is no easy way to automatically determine which development action (i.e. commit) is linked to which Jira issue without a reference. The reference must exist in the name of the development action (branch name, commit name, pull request title etc).
An example for a branch name might be PROJ-17-fix-null-pointer-exception which would cause the issue PROJ-17 to be linked (if it existed).
Smart Values
Various pieces of metadata in the development events (i.e. the branch name in a branch creation event or destination repository name in a pull request merged event) were exposed to users using AFJ’s Smart Values feature. It was important the team carefully crafted the smart values API so that we could support it going forward without making breaking changes. Furthermore, we had to ensure the API was git provider agnostic and did not rely on any special terminology or functionality offered by a specific git provider.
You can find documentation on DevOps/development smart values here.
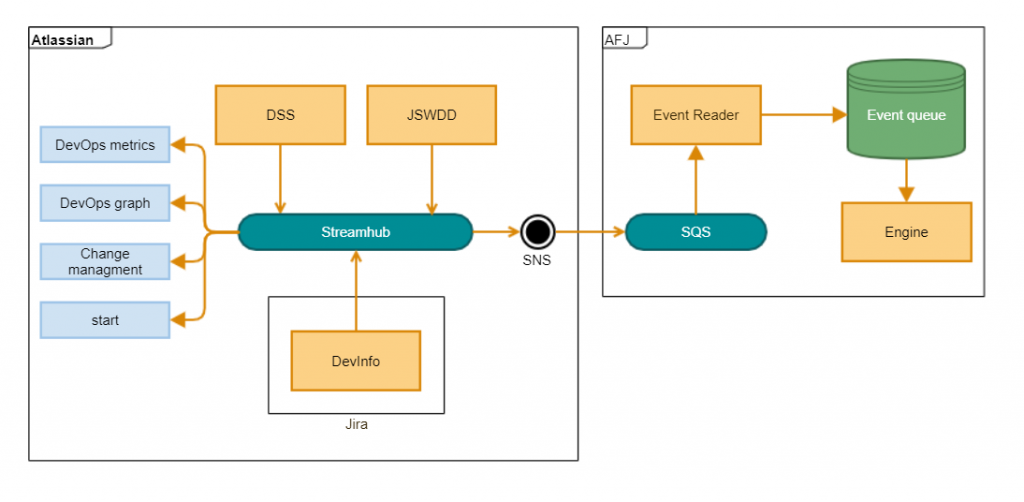
Infrastructure Diagram
This is the final infrastructure diagram that was designed by the team.
In this design, development events flow from the git provider through various internal services before finally landing onto Streamhub (an internal event bus). From here, events are consumed by an SNS topic. At this stage, the next step takes us outside the Atlassian AWS account and into the AFJ AWS account. SNS then pushes the events to an SQS subscriber. This SQS queue is polled by an event reader and stored in an event queue which is then processed by the AFJ engine.
1) Development information → Streamhub
There are a few sources for the development events that we use. Our goal here is to simply push the incoming development events to Streamhub (internal event bus) so that they can be processed later.
Development Status Service (DSS)
DSS is a constellation of microservices that is responsible for fetching information related to Jira tickets for a Jira project which has been integrated with a Bitbucket repository. Consider the development status panel which is shown on the issue view. This panel exposes development status information that has been linked to the issue via a Jira issue reference. In this example, we are using Bitbucket data retrieved via DSS.
We utilised DSS to push branch, commit and pull request Bitbucket events to Streamhub.
JSW Data Depot Service (JSWDD)
JSWDD is responsible for validating, transforming, storing and retrieving entity data associated with Jira issues.
We utilised JSWDD to push build and deployment events to Streamhub.
DevInfo
DevInfo allows us to enable third parties to push their development information to us. We utilise DevInfo to process development information originating from third-party git providers like Github and Gitlab.
2) Streamhub → AFJ
Once the development event is on Streamhub, we know it will be shortly processed. Streamhub is essentially a black box to us that takes in an event matching some predefined schema and pushes it to various consumers. In our case, the consumer was an SNS topic. It may seem odd that the SNS topic only has a single SQS consumer but keep in mind the SQS consumer was living in an entirely different AWS account. This provides us with some flexibility on the off chance that we need additional consumers in the future.
3) AFJ
Once the event had entered the SQS queue in the AFJ ecosystem, it would be polled by an Event Reader and stored on an Event queue for processing by the AFJ engine.
We will ignore the AFJ internal workings for the purposes of this blog post.
Scalability
One concern for the team was scaling our solution as the number of users inevitably grew as we rolled out to customers.
Streamhub is quite a mature service at Atlassian and we were confident we would not put any stress on it that it couldn’t handle as the goto event bus used across the company. We treated Streamhub as a black box and worked on ensuring that the rest of the pipeline on either side of Streamhub scaled well.
Another optimisation that was made was to add a DynamoDB filter in our pipeline. We cached a list of enabled rules per tenant and filtered out events that would not result in an automation execution. In other words, we filtered out events for customers with no enabled DevOps rules. This allowed us to significantly reduce the amount of stress on the AFJ engine and RDS database.
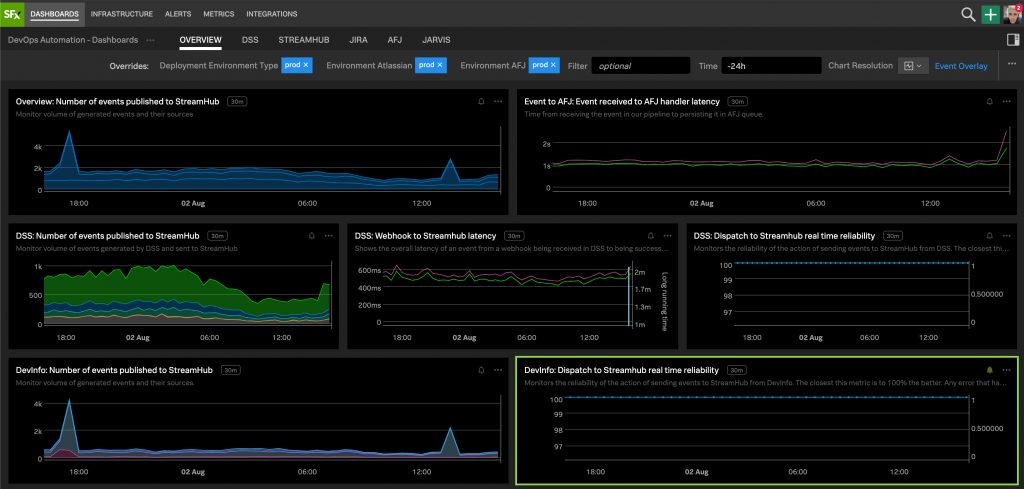
Observability
It was very important to the team that we had sufficient metrics and analytics in place as we rolled out these features to customers.
For metrics, we wanted to measure reliability and correctness across each stage of the pipeline. As a result, our metrics were largely broken down into the following categories:
- Development information → Streamhub
- Streamhub → AFJ
- AFJ
Grouping our metrics like this allowed us to quickly determine which part of the pipeline was experiencing a disruption in the case of an incident.
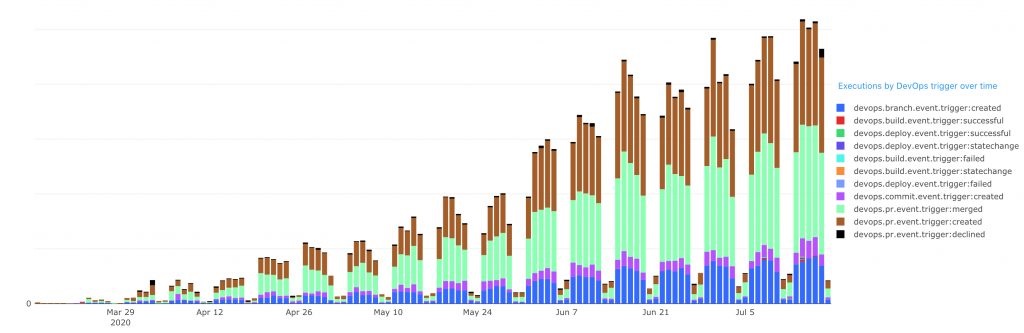
For analytics, we wanted to measure the uptick in usage as these features rolled out to customers. This allowed us to frequently re-evaluate priorities and focus on the areas that our customers were most interested in. The following graph shows the uptick in DevOps triggered AFJ rule executions over time.
Customer Feedback and Support
For more context please read the following announcement posts:
- New automation triggers across Jira Cloud, Bitbucket, GitLab & Github!
- New ‘Build and Deploy’ triggers for Jira automation!
If you have any feedback or questions on DevOps automation, please visit the Jira Automation space on the Atlassian community.