
Last week, Atlassian released Escalator, our Kubernetes autoscaler optimized for batch workloads, into the open source community. It is available from our Github repository.
Our journey from containers to Kubernetes
At Atlassian we have a long history of using containers to run our internal platform and services. This work started around 2013/2014, when we built our original PaaS based on Docker. From the containers in our microservices stacks, to jobs in a CI/CD workflow which build them, Docker provided a convenient way to package all of the dependencies together to ensure workloads can run everywhere. Whether it be on your laptop, or a dev, staging or production environment, containers have allowed us to make our services more reliable, deterministic, and require much less effort to run.
But not long into our container journey, it quickly became clear that there was a big piece of the puzzle missing: orchestration. There were four key missing pieces:
- We needed to schedule and place user pods on the compute infrastructure.
- We needed to ensure that our services stay-up even when cloud hardware failures occur.
- We needed to scale-up our infrastructure and applications to handle the peaks in an elastic user load.
- We needed to shut down unused virtual machines when they’re no longer needed to save money.
When designing our compute PaaS, we saw that Kubernetes would help provide us the platform to solve these challenges. Kubernetes could orchestrate our containers given its rich deployment capabilities, its declarative configuration and reconciliation loop architecture, and its enormous community support.
And so we built our Kubernetes platform tooling. We battle-hardened it for production, we built a dedicated Kubernetes team to help manage it, and we started migrating our existing container-based workloads to it. The dedicated team served (and continues to serve) a critical role: It enables our internal teams to leverage Kubernetes and not worry about how to run the platform itself – which keeps the internal teams focused on their most important task: developing great services.
One of the first workloads we migrated was our Build Engineering infrastructure, which Atlassian teams use for continuous integration and delivery to build and deploy products. Previously, this had been running on a cloud provider’s proprietary container management system, so the workload had already been “Dockerised” into containers. Our challenge was to take this big hairy workload, which in its peak consumes several thousand cores, and lift-and-shift it to Kubernetes.
Some problems fixed, a new problem discovered: The importance of good autoscaling
Initially with our Kubernetes platform, we were pleasantly surprised by how quickly we were able to port these batch workloads to Kubernetes pods. However, when the number of concurrent jobs ramped-up, we started to notice a few bumps in the road. Namely, the cluster wasn’t scaling-up or down fast enough.
Scaling up: When the cluster hit capacity, users would often have to wait minutes before additional Kubernetes workers were booted and able to service the load. This is not a great situation to have, because many builds couldn’t tolerate extended delays and would fail. The problem was that Kubernetes’ de-facto cluster-autoscaler service was missing a key feature: the ability to preemptively scale-up compute nodes before the cluster reaches capacity. Or more simply, the ability to maintain a fixed percentage of buffer capacity as insulation for spikes.
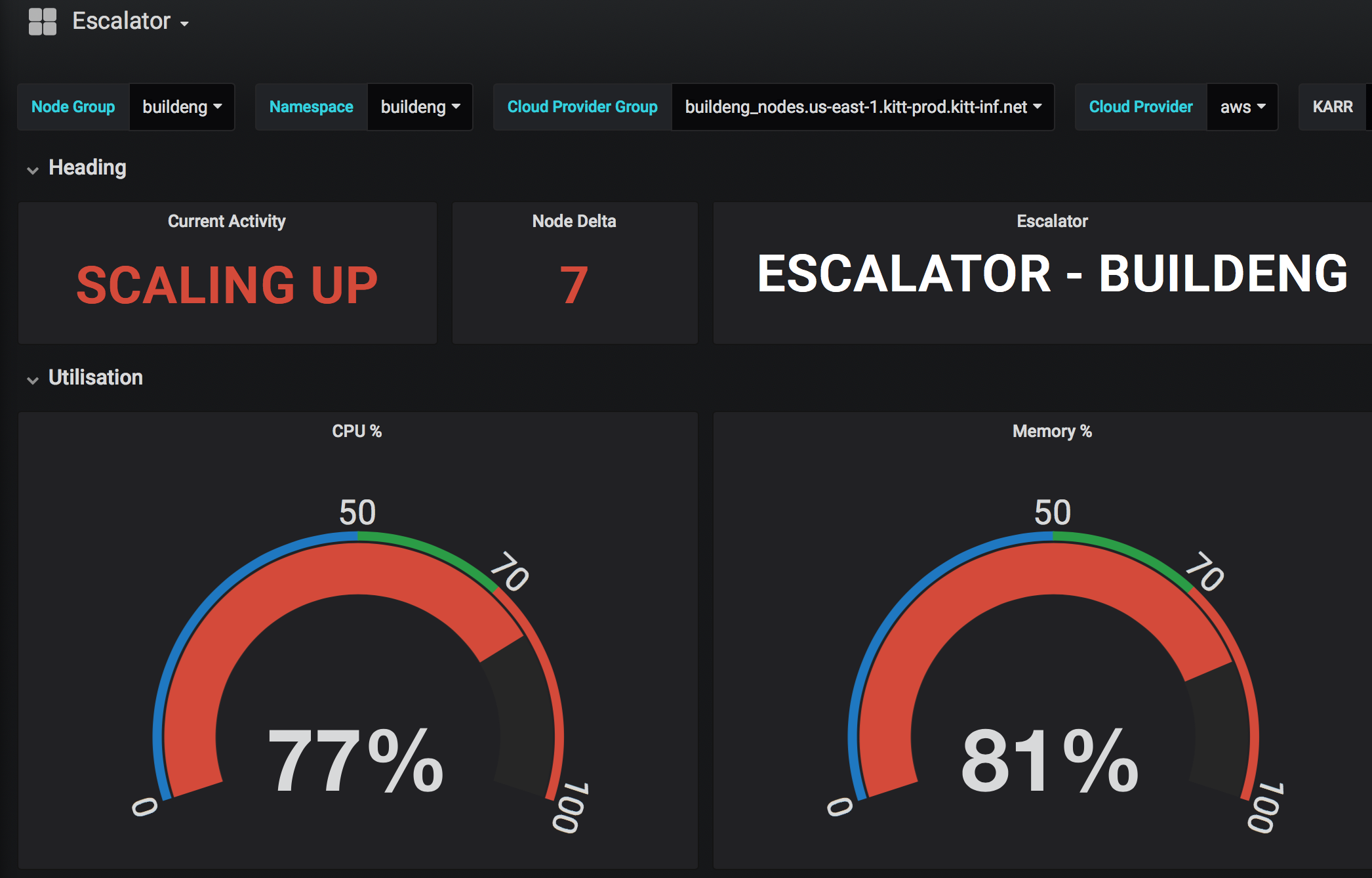
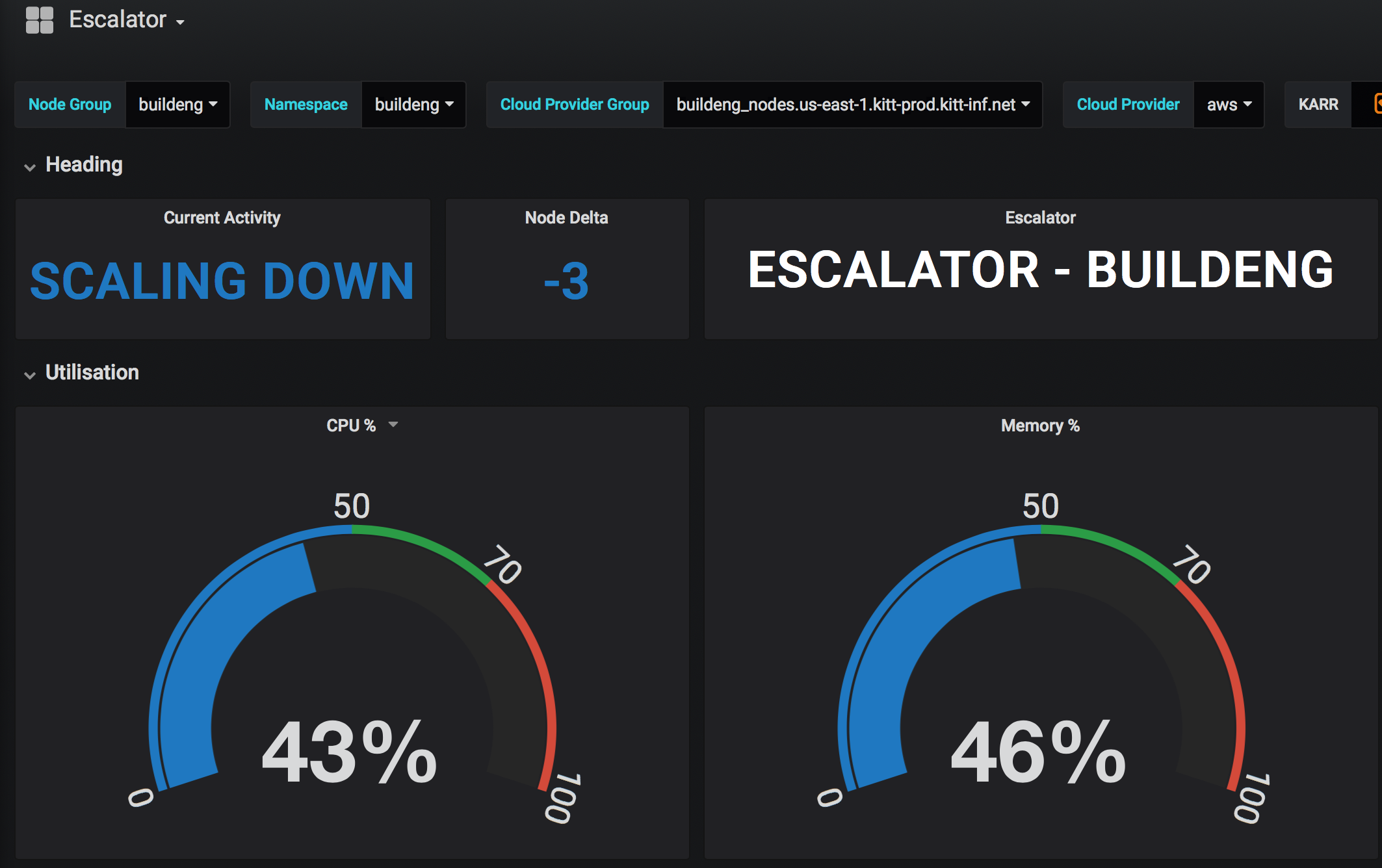
Scaling down: We also experienced the reverse problem: when the loads had subsided, the default autoscaler wasn’t scaling-down quickly enough. While this isn’t a huge problem when your node count is in the single digits, this changes dramatically when it reaches the hundreds and beyond. Then you’re suddenly burning a lot of money on idle compute that is left running when you no longer need it.
Building a better solution: Escalator
With the two scaling motivations in mind, our team set about examining the options. Do we extend the de-facto Kubernetes cluster-autoscaler? Was there another autoscaler we could leverage? Should we just develop our own autoscaler to optimize our jobs-based workload?
For a variety of reasons, we chose the later and set out on a new project, called Escalator. We envisioned a horizontal autoscaler optimized for batch workloads with two initial goals: provide preemptive scale-up with a buffer capacity feature to prevent users from experiencing the ‘cluster full’ situation, and support aggressive scale-down of machines when they were no longer required. We’d also want to build in something for our Ops team: Prometheus metrics to allow us to dig beneath the covers to see how well it was doing.

A few weeks into the project, we started to see the first fruits of this development: Escalator was supplementing Kubernetes’ standard cluster-autoscaler, such that it would ‘taint’ unused nodes. In this way, the cluster-autoscaler could more rapidly drain and remove the nodes from our autoscaling groups. We then worked to develop pre-emptive scale-up functionality, and provisioned it with configuration directives to allow users to specify a buffer capacity. The next milestone was to extend Escalator and build all the functionality for horizontal scaling, so it could work autonomously and entirely replace Kubernetes’ standard autoscaler for our jobs-based workloads.
After several months of work, the result was exactly what we envisioned to build, and what we’ve released into the open source community. Gone are our three minute waits for EC2 instances to boot and join the cluster. Instead pods transition from scheduled to running in seconds. This is made possible due to the pre-emptive scale-up functionality that we built in. It is provisioned with configuration directives, so users can specify a percentage slack capacity that suits them. Gone too is all the wasted money we were spending every hour on unused, idle worker nodes. The cluster now scales-down very quickly, so we only pay for the number of machines we actually need. Escalator has enabled us to save a lot of money – ranging from hundreds to thousands of dollars a day – based on the workloads we’re running. We also built in compatibility for using Prometheus metrics, which Ops teams will love.
What’s next
Today we’re using Escalator for both job-based internal workloads and for our Bitbucket Pipelines customers (who are also running on our Kubernetes Platform). We’re also exploring how we can manage more service-based workloads for other teams and products down the road. But given the tremendous benefits its delivered in our environment, we’ve released Escalator to the Kubernetes community as open source, so others can take advantage of its features too.
The source can be found on our Github account and we’d love to see what contributions you have for it. Be sure to checkout the roadmap to get an idea of where Escalator is heading, and please submit PRs and feature requests if you’d like to help shape its future.