
When it comes to infrastructure, Kubernetes and its associated ops discipline ClusterOps are definitely the hottest new tech to burst onto the scene for quite a while.
Now, sometimes that means that something’s just generated a lot of hype, but in Kubernetes’ case, the hype is deserved. The project is moving very fast, has a friendly, active community, and is already an amazing system. The aim of this blogpost is to tell you about what we’ve done to run Kubernetes on AWS in a (hopefully) scalable, reliable, and repeatable way and explain why we did it like that.
What is Kubernetes?
Kubernetes is an open-source project aiming to make it possible to run your Docker (or other container format) application in a scalable, reliable, and standard way across as much compute as you care to dedicate to it.
It’s based on the work done at Google on Borg and Omega, and has been started and given an initial push by Google. But the project has definitely taken on a life of its own and has active contributions. Not only from a lot of individual contributors but also from other large companies like Redhat, and Huawei, with lots of other companies building products and services on top of it as well.
What are we doing with Kubernetes?
A little bit of history
Our team is the Kubernetes Infrastructure Technology Team. (KITT for short 😉 , so we stuck with a Knight Rider theme for naming.) Before the formation of our team, many teams in Atlassian had started using Kubernetes. We spun up this team as a way to ensure we used economies of scale to our advantage by having one team build and run the diverse Kubernetes clusters that had sprung up, and also to allow other teams to use the power of Kubernetes’ declarative configuration and reconciliation loop without having to learn all of the fiddly bits.
The specifics of what we do with Kubernetes is the story of how our team has evolved in the last year.
We wanted three things:
- To use Kubernetes to improve our container orchestration and dev speed
- To shine on AWS
- To create a compliance-friendly production environment, with everything that is entailed to us, as sysadmins and Ops folk with long experience.
Building a layer-cake
To that end, we decided that we would break-up the infrastructure into three layers each having defined demarcation points:
- The base AWS configuration (Our rule was that we should use this for networking and other
administrative constructs, like certificates and base security groups)
- The compute infrastructure that actually runs Kubernetes (all the EC2 instances and associated administrivia, this layer provides a Kubernetes API as its final output)
- The things that run on top of Kubernetes (Anything that requires poking a Kubernetes API)
Once we decided on this layer-cake, we started by designing the first layer, which we named the FLAG. Our idea for the FLAG was to specify our configuration using a three-tuple of details: customer, environment, and region.
Here, ‘customer’ means ‘internal customer’ – this platform is for Atlassian internal use only, ‘environment’ is an arbitrary designator (most environments use some variation on dev/stg/prod), and ‘region’ means AWS region.
We used Terraform to implement the FLAG, as we wanted to have the ability to see what infra changes a particular config change will create before it’s deployed, as this was a requirement for our internal SOX-certification process. (remember the third goal!)
As we built the platform, we discovered an additional requirement: There should be as few as possible (preferably one) API endpoint for customers to talk to.
Dividing into cells
We preferred to follow the model of having single Kubernetes clusters exist inside only one AWS availability zone (AZ). (We pulled an idea from some stuff we’d read about GKE and called these ‘cells’).
The intent here was to minimize blast radius, to make failure domains easy to understand and reason about, and to treat both compute instances and entire clusters as cattle.
If something went seriously wrong in a cluster, we wanted the ability to throw it away and re-deploy a new one. With respect to High Availability (HA), redundancy, and Disaster Recovery (DR), our intent was (and is, eventually) to use cluster Federation.
This will one day provide our internal customers a single endpoint to talk to, and the facility to select their own availability requirements. However, for now, Federation does not meet our requirements, and so, we’ve decided to change our cells to be able to be split across AZs. Luckily, our networking model as described below supports both use cases.
So, recapping our three design decisions:
- Split the config into at least three layers
- Use terraform for our deployment/configuration tool
- Should allow for one cell per AWS AZ and one cell per AWS region.
Designing a network
Next on the task list was figuring out how we would design the network subnetting. In doing this, we wanted to ensure that it would be as scalable and extendable as possible.
However, in doing the research for this, I found that the Kubernetes project provides very little to no information about designing the network that it runs on. We needed to spend a lot of time digging into detailed documentation to find what the important numbers to take into account are – this blogpost is also an attempt to make some rough info about this available outside Atlassian.
For the diagrams below, I’ve included both variations – one cell == one AZ and one cell == three AZs. They’re broadly similar, but could serve as a starting point for your own networking design. We used 10.0.0.0/16 as the subnet for the VPC as a whole for purposes of illustration – we obviously don’t use that for real:
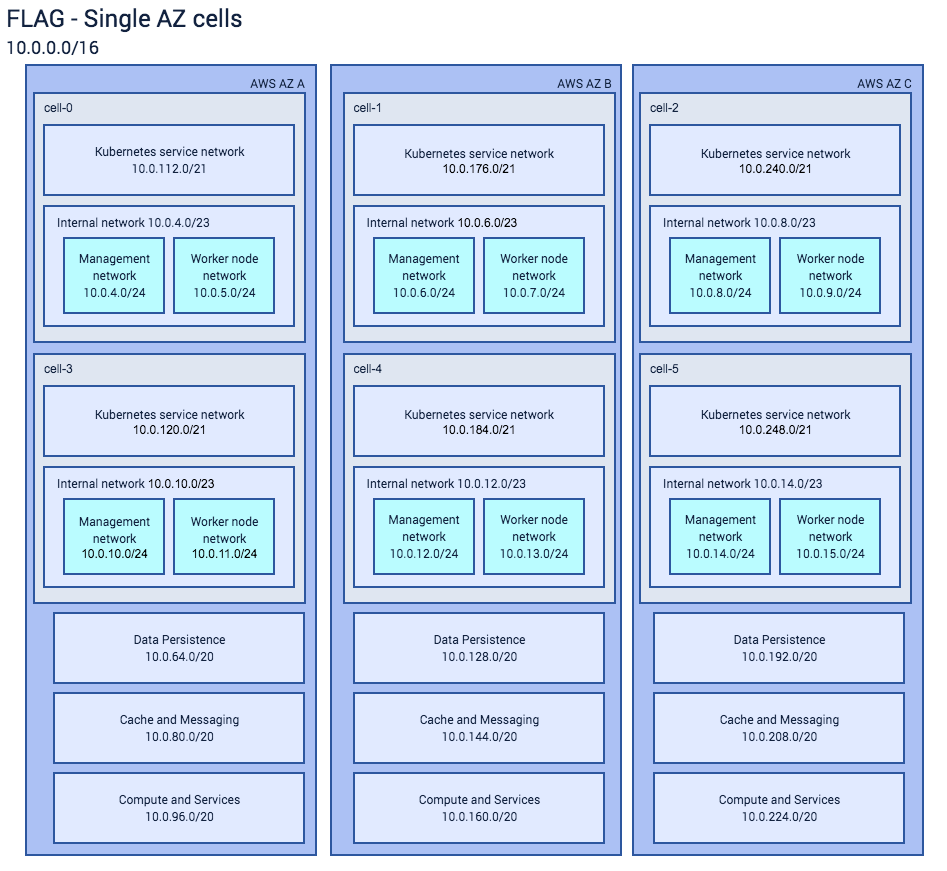
If looking at this gives you a headache, you’re not the only one! A lot of this requires explanation.
First, the size of the boxes is not related to the size of the subnet – there’s no way to make a remotely readable diagram spanning that many powers of two!
Second, you can see how we’ve allowed for six cells across three AZs. In regions where there’s only two AZs, we will only need four cells. Providing for more than one Kubernetes cell per AZ allows for scaling in the event that a cell hits some capacity limit.
I’ll explain more in a minute, but, in terms of IP addressing, we are able to scale to about 63,750 pods per AWS region. We expect we will not need this any time soon, but ‘640k should be enough for anyone’ is always in the back of our heads.
Now, the multi-AZ-cell diagram:
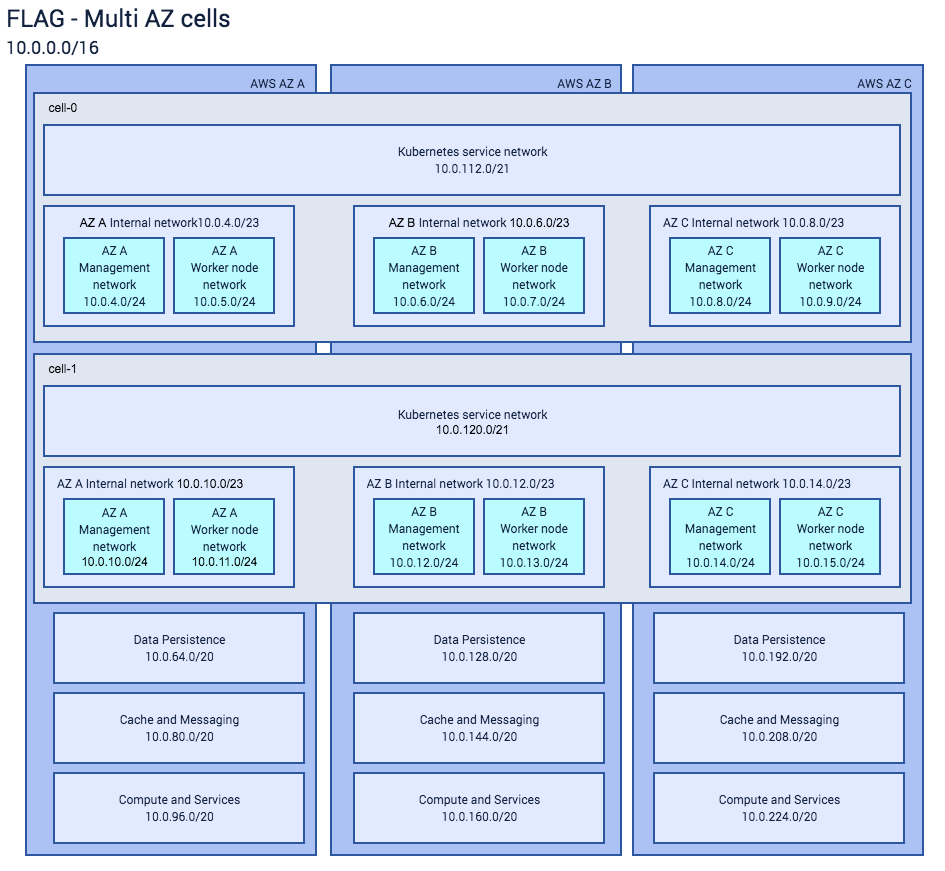
We’ve re-used a lot of the configuration we built for the single-cell case here. Important case-specific things to note here:
- Controller-manager nodes and etcd nodes are round-robined across the available Management networks. Since we always have exactly three etcd nodes, they are always in different subnets in this case (as we need to be able to withstand an AZ failure inside the cluster.)
- Worker nodes are likewise round-robined across the available Worker node networks
- and we’re relying on Kubernetes’ cloud vendor auto-detection to have Deployments spread across AZs in a sensible way.
We can still fit two cells into a FLAG, yay!
Subnet sizing
(For all the network subnet talk in the rest of this post, I’ll be using CIDR notation, that is, /x to indicate the subnet size)
There’s no entry for the network that contains the actual pod IP addresses. That’s because we allocate one /16 for that, and reuse it across cells, marked explicitly as non-routable everywhere we can. This is for two reasons.
First, we wanted to do whatever we could do to teach people the new rule that Kubernetes strongly implies – namely that an IP address is not a valid identifier any more. We assign IP addresses to pods in a transient and reusable way, so we need to get people out of the habit of using IP addresses as static identifiers. Reusing the pod network and making it non-routable is a hard enforcement of this rule.
Second, we didn’t want to have scaling problems about the number of pods in a cell for a long time. Initially, we started out using Flannel, and because of its requirement for having an equally sized subnet assigned to each worker node, using a /16 for the pod network allowed us to have 250 nodes running up to 255 pods each, for a total of 63750 pods, network-wise, in each cell. (Obviously, there are other capacity constraints here, especially the default 100-pod-per-node limit, but again, the intent was to allow this at a network level, and figure out the rest once we actually had a platform.)
Resource subnets
We’ve allocated some reasonably-sized networks in each AZ for three types of extra resources:
- Data Storage: any sort of persistent data store (RDS, Dynamo, internal S3 endpoints, Redshift endpoints etc.)
- Cache and Messaging: any sort of cache or messaging endpoint (Kafka, Elasticache, Redis, Memcache, etc)
- Compute: any extra compute (mostly for Lambdas and the like, we expect).
The intent here is to situate resources required for things running on the cluster running as close as possible to the pods that need them. We also allow clear subnets for things like Open Service Broker providers to drop into. Separating these by functional type also allows for easier construction of network ACLs – we can block access to everything but datastore access ports (postgres, mysql ports, etc.) from the node subnets, for example, to make accessing the management interfaces of any instances in there harder.
This pattern doesn’t change between the single-AZ and multi-AZ use cases.
As before, we were trying to make sure that addressing wasn’t a scaling limitation, so ensuring that ~4000 addresses were available for each of these subnets made us more confident that the scaling limits we run into will be a bit down the road.
Cell infrastructure networks
We’ve given each single-AZ cell a /23 in total for all its node and other infrastructure bits, including both managers (API Server nodes), etcd nodes, and Worker nodes. Management and etcd nodes live within the /24 management network, and Worker nodes inhabit another /24. (This is where the maximum of 250 nodes per cell originates). Obviously, a multi-AZ cell has three times the nodes available, but I think we will run into other capacity limitations long before we need ~760 nodes.
Kubernetes Service networks
In the single-AZ case, we’ve allocated each cell a /21 network (2040 addresses) for its service network, and in the multi-AZ case, we use the first /21 of the single-AZ service networks. Each Service object on the Kubernetes API needs an address from this subnet, so we wanted to allow for quite a few – we’re assuming that the service:pod ratio will be below 1:10 at least. No basis for that, just a guess. Also, since doing this design, we’ve seen from Haibin Xie and Quinton Hoole’s talk at Kubecon EU (https://youtu.be/4-pawkiazEg) that, at least until the fixes they worked out are merged, more than that is not a good idea.
Final Thoughts
We’ve been using this structure for about 8 months now, and have finally got to a stage where we have environments up and running that will be able to meet our compliance needs. They’re not quite ready, but they’re close. I hope that this can help others who are somewhere along their Kubernetes journey, and I’m happy to talk further about it either on twitter (@youngnick). Also, keep an eye on this blog for further posts about how our build and deploy workflow, how we do auth* for our clusters, and what we’re doing to secure the cluster internally.