

More than four years ago, Stash Bitbucket transitioned from running Javascript unit tests by Java to Karma.
Today, I can announce that we switched our test runner to a modern tool called Jest!
How did we end up here?
Before Jest, our testing framework was a combination of different tools and helpers wired up together:
- Babel
- QUnit
- Karma
- Headless Chrome
- RequireJS
- Squire
- Sinon
- Parable
Each of them serves a different purpose and is mandatory to write unit tests. The problem with that setup is that you need to maintain the custom integrations and this can cost you time and a lot of headaches. As you can guess, the complexity of this solution was evolving over time. There is no one to blame for that. A few years ago there was no other way to even think about running unit tests inside NodeJS only. Karma and PhantomJS were the only solutions if you wanted to think about unit tests for your Javascript code.
Those days are gone. We have more mature tools and, most importantly, more flexibility in how we want to provide and to run our unit tests.
Thanks to the jsdom project we can run the code that works in the browser without a browser.
Why did we have to migrate again?
It wasn’t just hype over a new shiny Javascript tooling. We had requirements that our old setup was not meeting:
As a developer, I want to test code that depends on the NPM module so that I can ensure my code works.
Let's say you have code that depends on one of the NPM packages. If you are lucky enough the package is published as a bundle with the UMD. Then if you want to wire a unit test in Bitbucket you only need to update a karma.conf.js file and provide the proper mapping between the NPM package name and a file location inside the node_modules directory. If for some reason you need to include multiple entry points from the NPM package, you need to repeat this step manually for every entry point you are using.
It's manual work that you can easily forget after you install a new NPM package or if someone else overlooked that. With Jest, you don't need to worry about that anymore. Jest will resolve the modules for you based on their names and configuration.
As a developer, I want to test code that depends on Atlaskit so that I know my components are working correctly.
With our Karma setup that was not possible. Atlaskit is shipping their components with only two formats, CJS and ESM, and soon they will ship only ESM. We need either AMD or UMD for our Karma runner.
This meant that Bitbucket was not able to load and run the ESM module without transpiling it. This can be solved with the help of parable package. You could manually whitelist some of the node_modules directories and transpile them using Babel.
Additionally, you need to either transpile all the internal modules into AMD or UMD format so the browser can load them and run during runtime. Atlaskit is written with a modern ESM code, so you will also need to update the karma.conf.js file and provide the mapping between all of the entry points and transpiled file paths.
A few weeks ago I wanted to write a unit test for one of the components that is using Atlaskit. I started investigating the problem and thinking about a possible solution. At the end of this day, after spending a few hours manually providing the mapping I decided to hold on for a while and stop. It was a total waste of my entering time. I didn't want to provide a missing integration between Karma, parable, babel, Atlaskit and webpack or browserify because I will only increase the complexity even more. At this point, I was close to finalizing the Jest migration and decided: now or never. We need to start using Jest. Now!
Why Jest?
One of the beneficial features of Jest is the ability to debug tests during the runtime. You can run the tests in the watch mode with —watch flag. When the watch mode is enabled the test will rerun every time you change the test or if you change the code that your test depends upon on. Let's say you have a unit test T1 that depends on module A and B, the module B depends on C and D, and module D depends on E and also test T2 depends on module E.
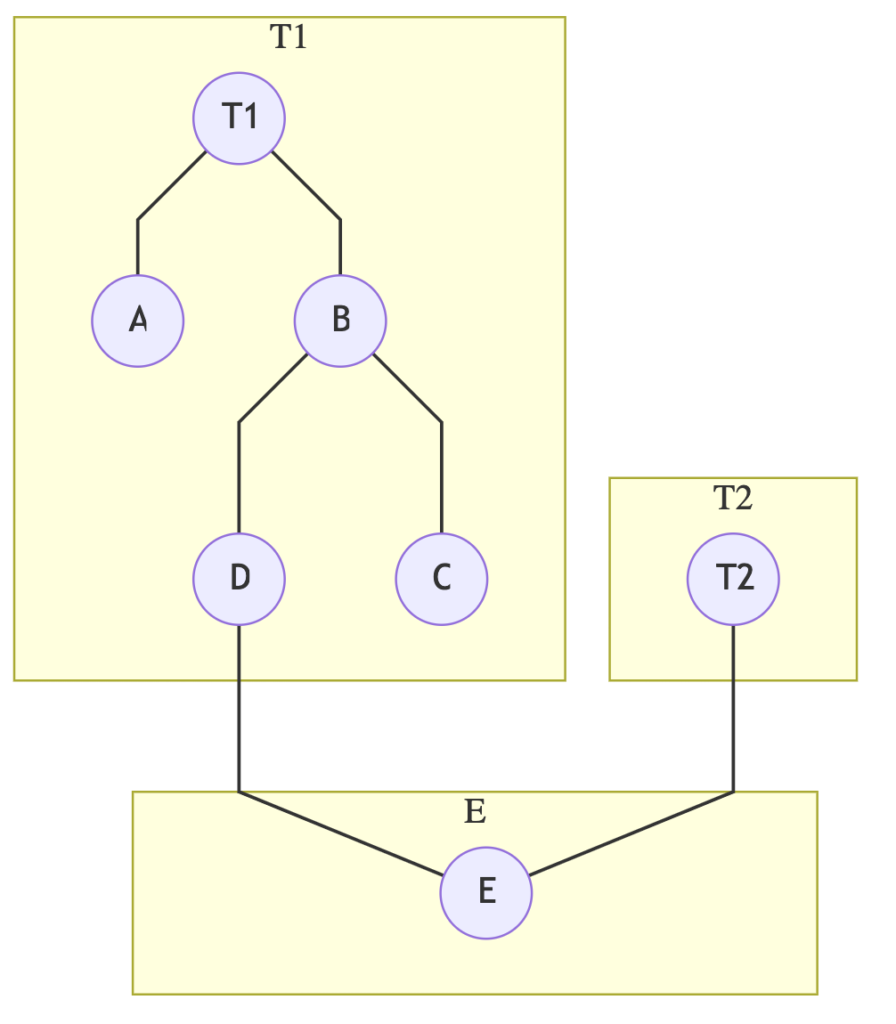
Every time you make a change in test T1 or T2 or any of the modules like, e.g. module E all the tests that are depending on it will be re-run. Thanks to that you can have instant feedback and check if the changes you introduced are not breaking the test.
What is even more important is that you can debug the test run thanks to node debugger. You can hook up Jest with the IDE and debug your tests in the editor. How cool is that?
Recently Google introduced a new project that is a standalone node debugging environment. It's built on top of Chrome DevTools UI that can be used to inspect and debug the code just like in regular DevTools. Personally, I found this really useful because you can have the same debugging experience as you do when you are debugging the code in the browser.
After we migrated to Jest, our testing framework stack was simplified from many tools into only two:
- Babel
- Jest
This is way simpler, isn't it?
For now, we still run our unit tests with a QUnit, Sinon and Squire syntax but this is the temporary solution, and the plan for the near future is to use a codemod to migrate the syntax to Jest.
Innovation time
I started working on the migration to Jest in May 2018.
During the breaks between projects, I was working on fixing the current unit tests so we could run them in Jest. It was tedious work that took me almost a year. I created more than 20 pull requests before finally merging the last one that enabled Jest on our Continuous Integration and on a local development environment.
There were plenty of different problems that had to be fixed, for example leaking data between the tests. Jest is using a sandbox mode and runs each spec in a separate context. Karma, on the other hand, runs all the tests in the same context. If your test depends on a mocked module or requires providing WRM dependency, it's easy to overlook that when you are working with Karma.
The most challenging problem was: How can we migrate our tests to Jest in iterations without having two different test runners over the migration period? After all, we still had to deliver the new product features and ensure our code is not broken.
The solution was to write a QUnit-like-jest bridge. Based on the QUnit documentation I provided exactly the same API and syntax but with Jest working under the hood. When the test was trying to run and execute QUnit.test('something') code, it will work with two different runners at the same time.


The problem with two different incompatible test runners was solved!
Is it a success, then?
… mostly. We were able to get rid of the custom framework and remove plenty of code from our repository. Precisely, we removed more than 8k lines of code from our codebase. We still need to migrate the old syntax with a codemod.
The migration to Jest unravelled one additional problem: our test coverage for Javascript is pretty low. Before we migrated to Jest, we had 73% aggregated coverage for our front-end code. This number includes the coverage collected for the test code which, in my opinion, is not a correct configuration.
So what is the real coverage value, then?
“In computer science, test coverage is a measure used to describe the degree to which the source code of a program is executed when a particular test suite runs.” https://en.wikipedia.org/wiki/Code_coverage
Have you ever thought for a second what it means to provide a 100% code coverage for your source code?
Does it mean that every line, every "if" statement, and every corner case is tested?
What about the case where you have two files A and B that are not depending on each other and your tests are covering 100% of the tests for file A but you don't have a test for file B. Does the coverage still equal 100%? Or maybe it’s 50%?
Those are the questions you should ask yourself when you measure the code coverage:
- Should I include only coverage for the files and modules I'm testing?
- Or should I also include the files that are not nested?
I would say the second option is more accurate if you want to stick to the facts. If you don't have any tests for file B, it means it's not covered, right?
Additionally, you shouldn't include a test’s runtime in the code coverage score. Those are not part of the application source code and don't give you much value when you think about the big picture of your project.
(By the way, one of our Marketplace vendors wrote a great post on how to use JaCoCo as a code coverage tool for Scala.)
Ugly truth
Sometimes you need to face the ugly truth. And the fact was our coverage level for Javascript code was not acceptable. It was below 50% if you still wanted to include the code from tests itself. The real coverage we should talk about was below 30%.
It means that every time I click the merge button in my pull requests, I'm only 1/3 confident that the code works as expected. That's a pretty low ratio, don't you agree?
You might be thinking right now, "Hey, Maciej, our CI is all green and shiny, so what do you expect from us?"
That's true; unit tests are not the only single source of truth. It doesn't mean we are doomed or that we need to call out the engineering health sprint and start writing Javascript unit tests.
We have plenty of browser functional tests that are covering the gaps, but unfortunately functional tests are quite expensive and hard to maintain. Just a reminder: in the test pyramid, those are the ones located at the very top of it, while the base of the pyramid is built from the unit tests. It means providing the unit tests at the early stage of the development process can save you not only a lot of time but also a lot of $$$.
Lessons learned
Migrating to Jest was the right thing to do, even though it seemed daunting at first. By iterating the changes over time, we avoided the pain of a big-bang type migration.
Having Jest in place enables us to write unit tests more efficiently. Now we can be more productive while using new modern tooling. Our level of code coverage for Bitbucket Server's front-end codebase is not awesome, but at least we can start improving that!