
Uptime is perhaps one of the most important operational aspects of cloud-based services. High performance and functionality is only good when services can stay up 100% of the time. Frequent outages not only cause disruption in regular usage but also cause tangible damage to your brand. Gone are those days where 3 nines and 4 nines were considered good standards of high availability. Consumers these days expect 100% availability and depend heavily on it. Imagine Google Maps being down for an upgrade or not getting emails because Office 365 is rebooting its servers. While it's important to follow good design patterns and keep your services scalable, that's still only half the story. Equally important is a healthy runtime for hardware, applications servers, and database servers. In this post I share some of the vital types of monitoring and tools needed.
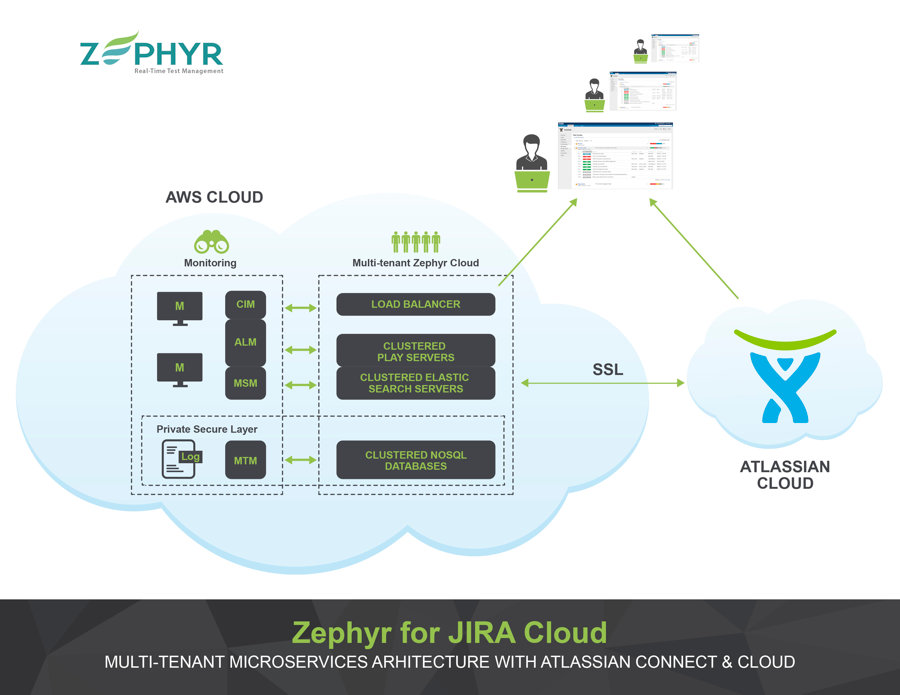
Core Infrastructure Monitoring (CIM)
What is CIM?
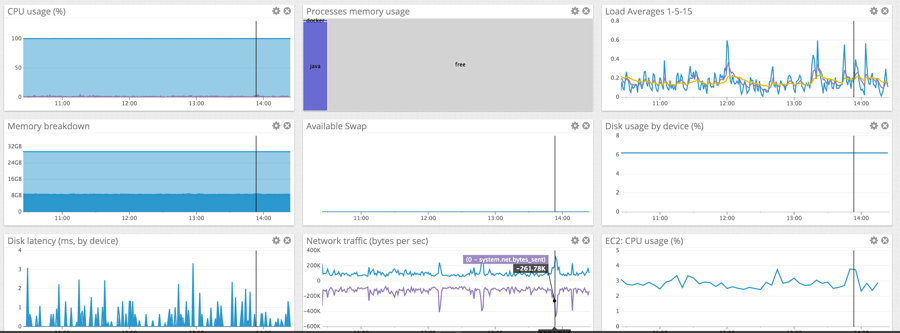
In modern cloud infrastructure, hardware failures are inevitable. Core Infrastructure Monitoring (CIM) is about detecting early signs of hardware related bottlenecks along with capturing hardware failure signals, and acting upon them before they become a larger issue. CIM includes monitoring health of hardware. Knowing the health of machines, CPU usage, memory consumption, and network bandwidth gives us insights into the current state of your infrastructure, its handling of your overall load and its scaling at various loads throughout the day.
Tools for CIM?
There are several great tools you can use to get a good sense of hardware health. In most cases, tools provided by your hosting provider (e.g. Amazon AWS, Heroku) should be sufficient for this purpose.
Metrics for CIM
- Avg. CPU usage
- Peak CPU duration
- Avg. memory usage
- Inbound and outbound bandwidth usage
Application Level Monitoring (ALM)
What is ALM?
Application Level Monitoring is all about monitoring the state of various servers, such as database servers, application servers, analytics servers, and Hadoop clusters. Parameters that are monitored are generally specific to the application and tools being monitored.
Tools for ALM?
There are several great tools for monitoring applications. Some great tools to consider are Datadog and New Relic.
Metrics for applications
- JVM process memory
- Internal thread count
- Disk IO
- Index read/write operations
Micro Service Monitoring (MSM)
What is MSM?
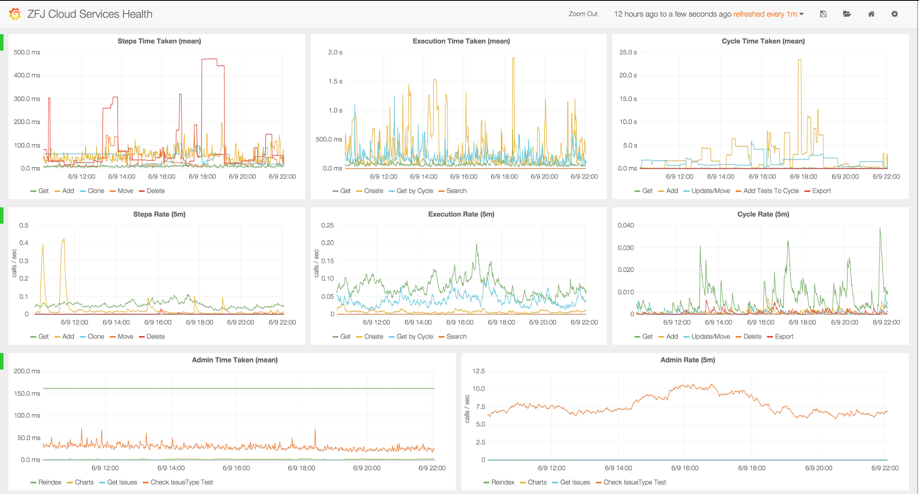
Microservices are an integral part of modern cloud architecture and are the king ping of horizontal scalability of cloud services. Whether you are running a traditional monolithic system or a well designed, well-orchestrated honeycomb of micro services, there will always be different API endpoints, different contracts to abide by, and different SLA requirements to fulfill. Microservice monitoring is all about monitoring throughput and the performance of every service – making sure SLA is met at all times. This kind of monitoring typically requires instrumenting the apps, making instrumentation configurable, and connecting it with a collector that can gather stats and periodically send them to a permanent storage, an analyzer and an alert system. This needs to be carefully designed as it can generate a lot of data and may impact app performance. You can avoid performance issues by creating groups of services and add configurability to switch on and off collection of each groups' monitoring data. Also, keeping collection period (e.g. every minute, every couple min) configurable also helps.
Tools for MSM
Storage engines e.g. GraphiteDB or InfluxDB and visualization tools e.g. Kibana or Grafana.
Metrics for microservices
- Maximum time taken
- Avg. time taken
- Avg. rate per min
- Peak rate daily
Multitenant Log Monitoring (MLM)
What is MLM?
Being able to monitor logs and deduce actionable insights or identify root causes following a problem is perhaps one of biggest challenges of multi-tenant deployments. There is a significant volume of logs generated for numerous clients. Having a single unique identifier (e.g. tenantId) should be the first level of log segregation. In addition, log statements should be grouped by requests. This becomes particularly important when a request makes hops between different services, each one generating some log message helpful in identifying the issue.
Tools for MLM?
Properly configured Classic ELK (Elasticsearch, Logstash, Kibana) stack. For more info on an ELK stack checkout this webinar.
Metrics for logs
- Logs per tenant
- Logs per request
- Total daily errors
What does it all mean?
To build well performing Atlassian Connect applications that will delight users, you need to spend the time setting up detailed monitoring. Great monitoring needs to cover everything from hardware, applications, and micro services. And if you've built a multitenant application, using a properly configured ELK stack will help you more quickly diagnose issues.