
The following is a repost of an article from my personal blog that describes how to perform event-driven updates from a PostgreSQL instance to Elasticsearch. In February I will be giving a tutorial at DeveloperWeek on development and testing with Docker, and this relies heavily on the code described in this post as an example project. So for consistency I am reproducing the post here. The final version of the code that will be used in the presentation is also available; I recommend downloading it if you are attending the sesssion.
Recently I've been evaluating Elasticsearch, and more specifically how to get data into Elasticsearch indices from source-of-truth databases. Elasticsearch is sometimes lumped in with the general NoSQL movement, but it's more usually used as secondary denormalised search system to accompany a more traditional normalised datastore, e.g. an SQL database.
The trick with this pattern is getting the data out of the master store and into the search store in an appropriate timeframe. While there is already a mechanism for updates from SQL databases in the form of the JDBC river ('rivers' being the Elasticsearch external data-feed mechanism); this operates by polling the database intermittently to retrieve any new or updated data. This is fine, and sufficient for most applications (e.g. an online storefront). However some of the systems I work on are less tolerant of delay (and as a rule I prefer event-based systems to polling), so I was curious to see if it's possible to implement event-driven updates from Postgresql that would propogate to the search cluster immediately.
tl;dr: It is, but requires some non-standard components; the steps required are described below, and a proof-of-concept test implementation exists. Also, this mechanism is not Elasticsearch specific, so could be applied to other secondary datastores (e.g. an Infinispan cache grid).
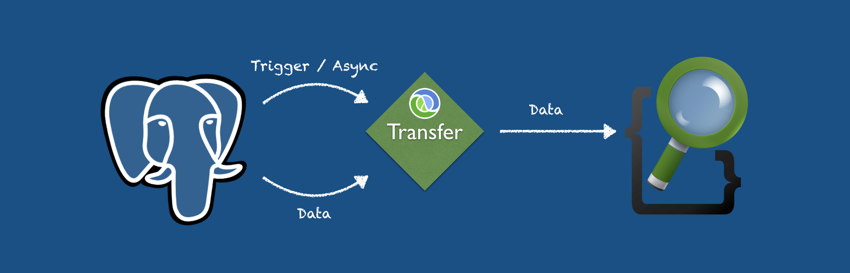
The basic idea behind this is pretty simple; we can use SQL triggers and PostgreSQL's notify extension to tell a dedicated gateway server that a change has occurred. notify/listen updates occur asynchronously, so this doesn't block the Postgres trigger procedure. The gateway then reads the changed data and injects it into the Elasticsearch cluster.
The first problem with this concept is that I’m working on a JVM platform, and the PostgreSQL Java driver doesn't actually support asynchronous updates via notify. It instead requires you to poll the server for any new notifications, effectively negating the benefits of using notify. In fact, the driver doesn't support a lot of newer Postgres features such as multi-dimensional arrays.
However while searching for possible workarounds for this I came across an alternative Java driver that attempts to fix the deficiencies in the current one, including adding true asynchronous notifications.
The second issue with this concept is that notifies are not queued; so if the gateway server is down for any period of time updates will be lost. One possible workaround is to maintain a modified column on the tables and read any newer entries on gateway startup. This is fine for simple data-models, but for more hierarchical data this rapidly becomes a maintenance pain (as child tables may need to trigger an update from the parent tables). The workaround for this is to implement an intermediate staging table that stores references to updated data; on each update the gateways reads from it and then deletes the reference; on startup it is read for any unretrieved references that occurred during downtime.
So the final workflow looks like:
- Create a trigger against any tables that need to be pushed to the search cluster on modification.
- The trigger calls a function that adds a reference to the staging table, then raises a notification with that reference as the payload.
- On notification the gateway reads referenced data, pushes it to the search cluster and then deletes the reference in the staging table. This should be done in a transaction to avoid loss of references in case of a crash.
- On startup the gateway performs a read/update of any outstanding references from the staging table and then deletes them.
As a test of the principles I've implemented a Clojure-based proof-of-concept project that will propogate changes between a PostgreSQL server and an ElasticSearch cluster in <500ms; these results are for a PostgreSQL server and Elasticsearch node running inside a Vagrant/Virtualbox VM on a standard rotating disk, so I'd expect to see better results in a tuned production environment. If you're interested in trying this yourself the gateway, Vagrant config and test code is all available in Bitbucket.